[Cursor-Guide]コンテキストの操作
LLMにおけるコンテキストウィンドウ、インテントコンテキストとステートコンテキストの違い、Cursorがトークンを使用してコード提案を生成する方法について学びます。AI支援コーディングの必須ガイド。
[Cursor-Guide]コンテキストの操作
オリジナルリンク: オリジナルリンク
まず、コンテキストウィンドウとは何でしょうか?そして、Cursorで効果的にコーディングする際にどのように関係するのでしょうか?
少し視野を広げると、大規模言語モデル(LLM)は、膨大なデータセットからパターンを学習してテキストを予測・生成するように訓練された人工知能モデルです。これは、あなたの入力を理解し、過去に見た内容に基づいてコードやテキストを提案することで、Cursorのようなツールを動かしています。
トークンはこれらのモデルの入力と出力です。トークンはテキストの塊で、多くの場合単語の断片であり、LLMはこれを一つずつ処理します。モデルは一度に文全体を読むのではなく、前に来たトークンに基づいて次のトークンを予測します。
テキストがどのようにトークン化されるかを見るには、このようなトークナイザーを使用できます。

コンテキストとは?
Cursorでコード提案を生成する際、「コンテキスト」とは、モデルに提供される情報(「入力トークン」の形で)を指し、モデルはこれを使用して後続の情報(「出力トークン」の形で)を予測します。
コンテキストには2つのタイプがあります:
- インテントコンテキストは、ユーザーがモデルから得たいものを定義します。例えば、システムプロンプトは通常、ユーザーがモデルにどのように振る舞ってほしいかについての高レベルの指示として機能します。Cursorで行われる「プロンプティング」の大部分はインテントコンテキストです。「そのボタンを青から緑に変えて」は、明示的なインテントの例です。これは規範的です。
- ステートコンテキストは、現在の世界の状態を記述します。Cursorにエラーメッセージ、コンソールログ、画像、コードの塊を提供することは、状態に関連するコンテキストの例です。これは記述的であり、規範的ではありません。
これら2種類のコンテキストは、現在の状態と望ましい将来の状態を記述することで協調して動作し、Cursorが有用なコーディング提案を行うことを可能にします。
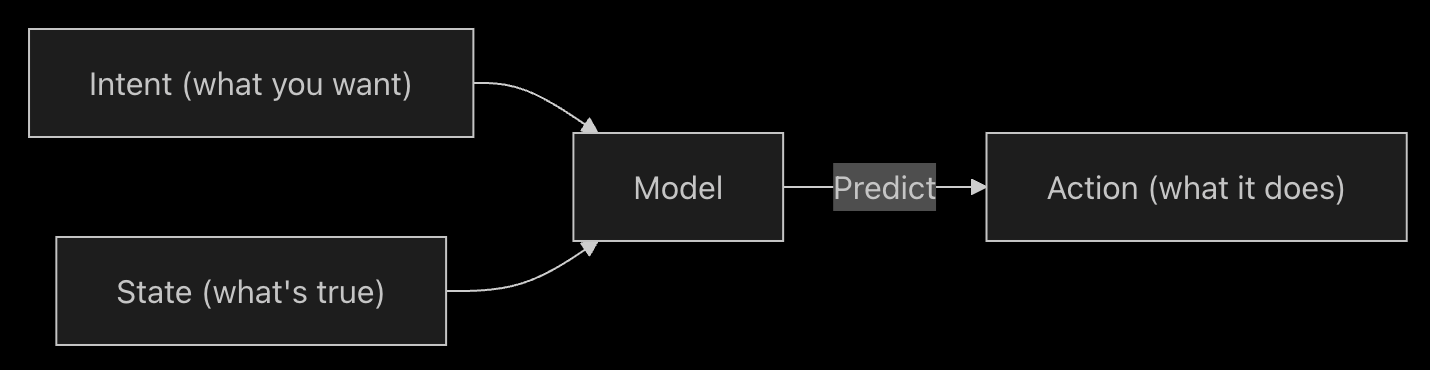
Cursorでのコンテキスト提供
モデルに関連性の高いコンテキストを提供すればするほど、より有用になります。Cursorで十分なコンテキストが提供されない場合、モデルは関連情報なしで問題を解決しようとします。これにより、通常以下の結果が生じます:
- モデルがパターンマッチングを試み(パターンがない場合)、予期しない結果を引き起こす「幻覚」が発生します。これは、
claude-3.5-sonnetのようなモデルに十分なコンテキストが与えられていない場合に頻繁に起こります。 - エージェントがコードベースを検索し、ファイルを読み、ツールを呼び出すことで、自分でコンテキストを収集しようとします。強力な思考モデル(
claude-3.7-sonnetなど)はこの戦略でかなり遠くまで行けますが、適切な初期コンテキストを提供することが軌道を決定します。
良いニュースは、Cursorはコンテキスト認識をコアに構築されており、ユーザーからの最小限の介入で済むように設計されていることです。Cursorは自動的に、モデルが関連すると推定するコードベースの部分(現在のファイル、他のファイルの意味的に類似したパターン、セッションからの他の情報など)を取り込みます。
しかし、取り込むことができるコンテキストはたくさんあるので、タスクに関連するとわかっているコンテキストを手動で指定することは、モデルを正しい方向に導くのに役立ちます。
@-シンボル
明示的なコンテキストを提供する最も簡単な方法は、@-シンボルを使用することです。これは、どのファイル、フォルダ、ウェブサイト、または他のコンテキストの一部を含めたいかが具体的にわかっている場合に最適です。具体的であればあるほど良いです。以下は、コンテキストをより詳細に指定する方法の内訳です:
| シンボル | 例 | 使用例 | 欠点 |
|---|---|---|---|
@code | @LRUCachedFunction | 生成する出力に関連する関数、定数、またはシンボルを知っている | コードベースに関する多くの知識が必要 |
@file | cache.ts | どのファイルを読み取るか編集すべきか知っているが、ファイル内の正確な場所はわからない | ファイルサイズによっては、手元のタスクに関係のない多くのコンテキストを含む可能性がある |
@folder | utils/ | フォルダ内のすべてまたは大部分のファイルが関連している | 手元のタスクに関係のない多くのコンテキストを含む可能性がある |

ルール
ルールは、あなたやチームの他のメンバーがアクセスできるようにしたい長期記憶と考えるべきです。ドメイン固有のコンテキスト、ワークフロー、フォーマット、その他の慣習をキャプチャすることは、ルールを書くための良い出発点です。
ルールは、既存の会話から/Generate Cursor Rulesを使用して生成することもできます。多くのプロンプトを含む長いやり取りがあった場合、後で再利用したい有用な指示や一般的なルールがおそらくあるでしょう。

MCP(Model Context Protocol)
Model Context Protocolは、Cursorにアクションを実行したり外部コンテキストを取り込んだりする能力を与えることができる拡張レイヤーです。開発環境に応じて、さまざまなタイプのサーバーを活用することが考えられますが、特に有用な2つのカテゴリは以下の通りです:
- 内部ドキュメント:例:Notion、Confluence、Google Docs
- プロジェクト管理:例:Linear、Jira
APIを通じてコンテキストにアクセスしアクションを実行する既存のツールがある場合、それ用のMCPサーバーを構築できます。構築方法の簡単なガイドはこちら:https://modelcontextprotocol.io/tutorials/building-mcp-with-llms

セルフギャザリングコンテキスト
多くのユーザーが採用している強力なパターンは、エージェントに短命のツールを書かせ、それを実行してより多くのコンテキストを収集させる方法です。これは、コードが実行される前に人間が確認する「human-in-the-loop」ワークフローで特に効果的です。
例えば、コードにデバッグステートメントを追加して実行し、モデルに出力を検査させることで、静的に推論できなかった動的コンテキストにアクセスできます。
Pythonでは、以下のようにエージェントに促すことができます:
- コードの関連部分にprint("debugging: ...")ステートメントを追加する
- ターミナルを使用してコードまたはテストを実行する
エージェントはターミナル出力を読み取り、次に取るべきアクションを決定します。核心となる考え方は、エージェントに静的コードだけでなく実際のランタイム動作へのアクセスを許可することです。

要点
- コンテキストは効果的なAIコーディングの基礎であり、意図(何をしたいか)と状態(何が存在するか)で構成されます。両方を提供することでCursorは正確な予測を行えます。
- 自動的なコンテキスト収集だけに頼るのではなく、@記号(@code、@file、@folder)を使った精密なコンテキストでCursorを正確に導きます。
- 繰り返し可能な知識をルールとしてキャプチャしチーム全体で再利用し、Model Context ProtocolでCursorの機能を拡張して外部システムと接続します。
- コンテキストが不足すると虚構(hallucination)や非効率を招き、関連性のないコンテキストが多すぎると信号が希釈されます。最適な結果を得るためには適切なバランスを見つけることが重要です。