[Cursor-Guide]Arbeiten mit Kontext
Erfahren Sie mehr über Kontextfenster in LLMs, Intent- vs. State-Kontext und wie Cursor Tokens zur Generierung von Code-Vorschlägen nutzt. Ein essenzieller Leitfaden für KI-unterstütztes Programmieren.
[Cursor-Guide]Arbeiten mit Kontext
Original-Link: Original-Link
Zunächst: Was ist ein Kontextfenster? Und wie hängt es mit effektivem Programmieren in Cursor zusammen?
Um etwas auszuzoomen: Ein großes Sprachmodell (Large Language Model, LLM) ist ein KI-Modell, das darauf trainiert ist, Text vorherzusagen und zu generieren, indem es Muster aus riesigen Datensätzen lernt. Es treibt Tools wie Cursor an, indem es Ihre Eingabe versteht und basierend auf bisher Gelerntem Code- oder Textvorschläge macht.
Tokens sind die Ein- und Ausgaben dieser Modelle. Es sind Textabschnitte, oft Teile eines Wortes, die ein LLM nacheinander verarbeitet. Modelle lesen nicht ganze Sätze auf einmal; sie sagen den nächsten Token basierend auf den vorherigen voraus.
Um zu sehen, wie ein Text tokenisiert wird, können Sie einen Tokenizer wie diesen verwenden.

Was ist Kontext?
Wenn wir in Cursor einen Code-Vorschlag generieren, bezieht sich „Kontext“ auf die Informationen, die dem Modell bereitgestellt werden (in Form von „Input-Tokens“) und die das Modell nutzt, um nachfolgende Informationen (in Form von „Output-Tokens“) vorherzusagen.
Es gibt zwei Arten von Kontext:
- Intent-Kontext (Intent Context) definiert, was der Nutzer vom Modell erhalten möchte. Ein System-Prompt dient meist als übergeordnete Anleitung dafür, wie sich das Modell verhalten soll. Der Großteil des „Promptings“ in Cursor fällt unter Intent-Kontext. „Ändere die Farbe des Buttons von Blau zu Grün“ ist ein Beispiel für einen expliziten Intent; es ist vorschreibend.
- State-Kontext (State Context) beschreibt den aktuellen Zustand der Umgebung. Fehlermeldungen, Konsolenlogs, Bilder oder Code-Abschnitte, die Cursor bereitgestellt werden, sind Beispiele für State-Kontext. Es ist beschreibend, nicht vorschreibend.
Zusammen arbeiten diese beiden Kontextarten harmonisch, indem sie den aktuellen Zustand und den gewünschten zukünftigen Zustand beschreiben, was Cursor ermöglicht, nützliche Code-Vorschläge zu machen.
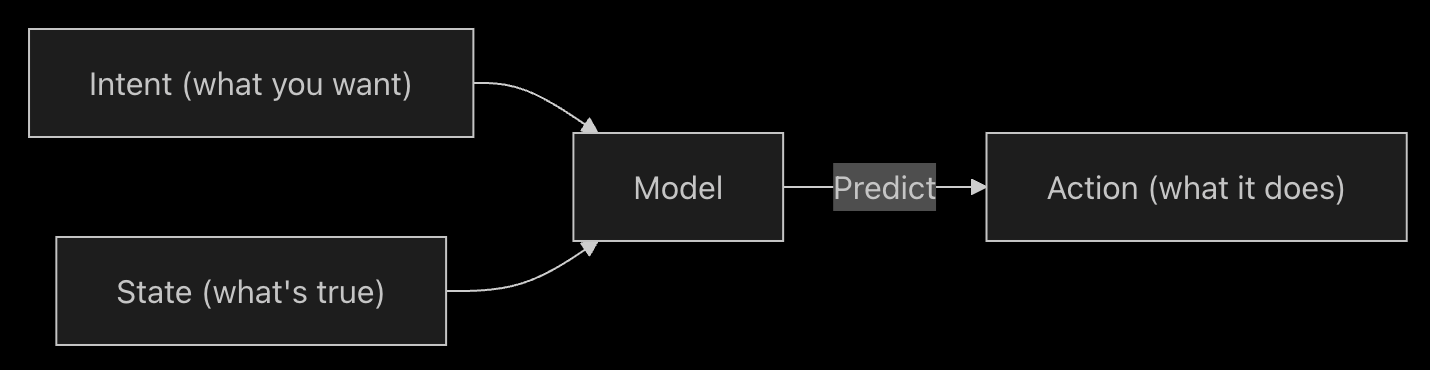
Kontext in Cursor bereitstellen
Je relevanter der Kontext, den Sie einem Modell bereitstellen, desto nützlicher wird es sein. Wenn in Cursor nicht genug Kontext gegeben wird, versucht das Modell, das Problem ohne die relevanten Informationen zu lösen. Das führt typischerweise zu:
- Halluzinationen, bei denen das Modell versucht, Muster zu erkennen (wo keine existieren), was zu unerwarteten Ergebnissen führt. Dies passiert häufig bei Modellen wie
claude-3.5-sonnet, wenn nicht genug Kontext gegeben wird. - Der Agent versucht, selbst Kontext zu sammeln, indem er die Codebase durchsucht, Dateien liest und Tools aufruft. Ein starkes Denkmodell (wie
claude-3.7-sonnet) kann damit weit kommen, aber der richtige initiale Kontext bestimmt die weitere Richtung.
Die gute Nachricht ist, dass Cursor mit kontextueller Wahrnehmung als Kernfunktion entwickelt wurde und darauf ausgelegt ist, minimalen Nutzereingriff zu erfordern. Cursor zieht automatisch die Teile Ihrer Codebase ein, die das Modell als relevant einschätzt, wie die aktuelle Datei, semantisch ähnliche Muster in anderen Dateien und weitere Informationen aus Ihrer Sitzung.
Es gibt jedoch viel Kontext, der herangezogen werden kann, daher ist das manuelle Spezifizieren von bekannt relevantem Kontext eine hilfreiche Methode, um die Modelle in die richtige Richtung zu lenken.
@-Symbol
Die einfachste Möglichkeit, expliziten Kontext bereitzustellen, ist das @-Symbol. Dies ist ideal, wenn Sie genau wissen, welche Datei, welcher Ordner, welche Website oder welches andere Kontextelement Sie einbeziehen möchten. Je spezifischer, desto besser. Hier eine Übersicht, wie Sie präziser mit Kontext umgehen können:
| Symbol | Beispiel | Anwendungsfall | Nachteil |
|---|---|---|---|
@code | @LRUCachedFunction | Sie wissen, welche Funktion, Konstante oder welches Symbol für die Ausgabe relevant ist | Erfordert viel Wissen über die Codebase |
@file | cache.ts | Sie wissen, welche Datei gelesen oder bearbeitet werden soll, aber nicht genau wo in der Datei | Kann je nach Dateigröße viel irrelevanten Kontext einbeziehen |
@folder | utils/ | Alle oder die meisten Dateien in einem Ordner sind relevant | Kann je nach Ordnerinhalt viel irrelevanten Kontext einbeziehen |

Regeln
Sie sollten sich Regeln als Langzeitgedächtnis vorstellen, auf das Sie oder andere Teammitglieder zugreifen können. Domänenspezifischen Kontext zu erfassen, einschließlich Workflows, Formatierungen und anderen Konventionen, ist ein guter Ausgangspunkt für das Schreiben von Regeln.
Regeln können auch aus bestehenden Konversationen mit /Generate Cursor Rules generiert werden. Wenn Sie eine lange, hin und her gehende Konversation mit vielen Prompts hatten, gibt es wahrscheinlich einige nützliche Anweisungen oder allgemeine Regeln, die Sie später wiederverwenden möchten.

MCP
Model Context Protocol ist eine Erweiterungsebene, mit der Sie Cursor-Fähigkeiten bereitstellen können, um Aktionen durchzuführen und externe Kontexte einzubinden.
Abhängig von Ihrer Entwicklungsumgebung möchten Sie möglicherweise verschiedene Arten von Servern nutzen, aber zwei Kategorien, die sich als besonders nützlich erwiesen haben, sind:
- Interne Dokumentation: z.B. Notion, Confluence, Google Docs
- Projektmanagement: z.B. Linear, Jira
Falls Sie bereits Tools für den Zugriff auf Kontexte und die Durchführung von Aktionen über eine API haben, können Sie einen MCP-Server dafür erstellen. Hier eine kurze Anleitung zum Bau solcher Server: https://modelcontextprotocol.io/tutorials/building-mcp-with-llms.

Selbst-erfassender Kontext
Ein leistungsstarkes Muster, das viele Nutzer anwenden, besteht darin, dem Agenten (Agent) kurzlebige Tools schreiben zu lassen, die er dann ausführen kann, um weitere Kontexte zu sammeln. Dies ist besonders effektiv in Workflows mit menschlicher Kontrolle (human-in-the-loop), bei denen Sie den Code überprüfen, bevor er ausgeführt wird.
Zum Beispiel gibt das Hinzufügen von Debugging-Anweisungen zu Ihrem Code, das Ausführen des Codes und das Überlassen der Auswertung der Ausgabe dem Modell Zugriff auf dynamische Kontexte, die es statisch nicht ableiten könnte.
In Python können Sie dies erreichen, indem Sie den Agenten anweisen:
- print("debugging: ...")-Anweisungen in relevanten Codeabschnitten hinzuzufügen
- Den Code oder Tests über das Terminal auszuführen
Der Agent wird die Terminalausgabe lesen und entscheiden, was als Nächstes zu tun ist. Der Kernidee besteht darin, dem Agenten Zugriff auf das tatsächliche Laufzeitverhalten zu geben, nicht nur auf den statischen Code.

Wichtige Erkenntnisse
- Kontext ist die Grundlage für effektives KI-gestütztes Programmieren und besteht aus Absicht (was Sie wollen) und Zustand (was existiert). Die Bereitstellung beider Aspekte hilft Cursor, präzise Vorhersagen zu treffen.
- Verwenden Sie gezielte Kontexte mit @-Symbolen (@code, @file, @folder), um Cursor präzise zu steuern, anstatt sich ausschließlich auf automatische Kontexterfassung zu verlassen.
- Erfassen Sie wiederwendbares Wissen in Regeln für die teamweite Wiederverwendung und erweitern Sie die Fähigkeiten von Cursor mit dem Model Context Protocol, um externe Systeme zu verbinden.
- Unzureichender Kontext führt zu Halluzinationen oder Ineffizienz, während zu viel irrelevanter Kontext das Signal verwässert. Finden Sie die richtige Balance für optimale Ergebnisse.