[Cursor-Guide]上下文应用指南
了解大语言模型中的上下文窗口、意图上下文与状态上下文的区别,以及Cursor如何利用token生成代码建议。AI辅助编程必备指南。
[Cursor-Guide]上下文应用指南
原始链接: 原始链接
首先,什么是上下文窗口?它如何影响使用Cursor进行高效编程?
宏观来看,大语言模型(LLM)是一种通过海量数据学习文本模式的人工智能模型,能够预测和生成文本。这类模型通过理解用户输入,基于历史学习经验提供代码或文本建议,从而驱动Cursor等工具的运行。
Token是这些模型的输入输出单元。它们通常是单词片段形式的文本块,由LLM逐个处理。模型不会一次性读取整个句子,而是根据已有token预测下一个token。
要查看文本如何被token化,可以使用这个tokenizer工具。

什么是上下文?
在Cursor生成代码建议时,"上下文"指以"输入token"形式提供给模型的信息,模型据此预测后续的"输出token"。
上下文分为两类:
- 意图上下文:定义用户期望从模型获得的结果。例如系统提示(system prompt)通常作为高层级指令,指导模型行为表现。Cursor中的大部分"提示"都属于意图上下文。"将按钮从蓝色改为绿色"就是典型声明式意图。
- 状态上下文:描述当前环境状态。向Cursor提供错误信息、控制台日志、图像或代码片段都属于状态上下文。它是描述性的,而非指令性的。
这两类上下文协同工作,分别描述当前状态和期望目标状态,使Cursor能够生成实用的编码建议。
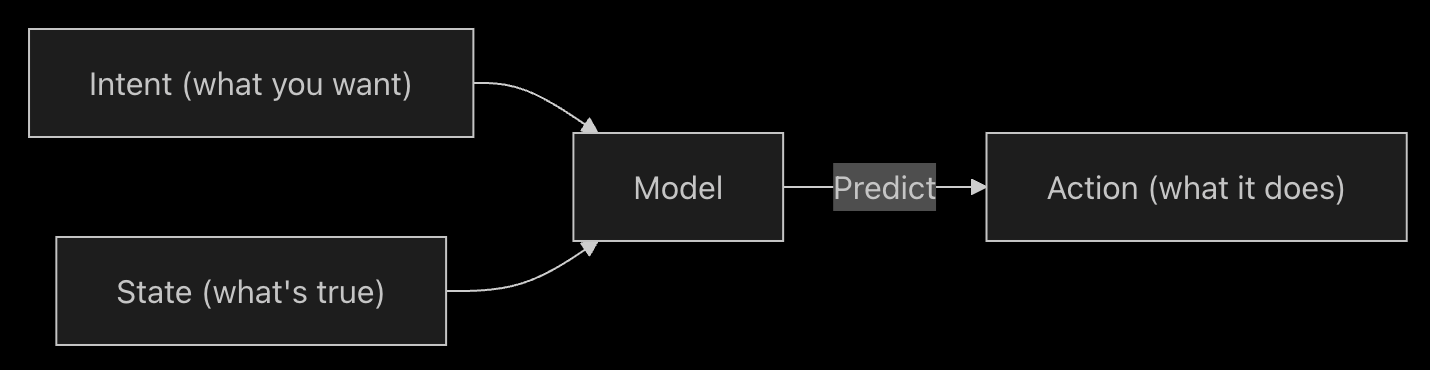
在Cursor中提供上下文
为模型提供的相关上下文越多,其输出就越实用。如果Cursor中上下文不足,模型会尝试在缺乏相关信息的情况下解决问题,通常导致:
- 幻觉现象:当模型尝试匹配不存在的模式时会产生意外结果。对于
claude-3.5-sonnet等模型,在上下文不足时这种情况经常发生。 - 代理自主收集上下文:通过搜索代码库、读取文件、调用工具等方式。强大的思维模型(如
claude-3.7-sonnet)能较好执行此策略,但提供正确的初始上下文将决定后续轨迹。
好消息是Cursor以上下文感知为核心设计,需要用户干预的情况极少。Cursor会自动提取模型认为相关的代码库部分,包括当前文件、其他文件中语义相似的代码模式,以及会话中的其他信息。
但由于可提取的上下文范围广泛,手动指定已知与任务相关的上下文仍是引导模型正确方向的有效方法。
@符号
提供显式上下文最简便的方式是使用@符号。当明确知道需要包含哪个文件、文件夹、网站或其他上下文时,这种方法非常有效。越具体越好。以下是精准控制上下文的分解说明:
| 符号 | 示例 | 使用场景 | 缺点 |
|---|---|---|---|
@code | @LRUCachedFunction | 明确知道哪些函数、常量或符号与输出相关 | 需要深入了解代码库 |
@file | cache.ts | 知道需要读取/编辑哪个文件,但不清楚具体位置 | 文件过大时可能包含无关内容 |
@folder | utils/ | 文件夹内全部或大部分文件都相关 | 可能包含当前任务不需要的内容 |

规则
规则应视为您或团队成员需要长期记忆的内容。记录领域特定的上下文(包括工作流程、格式规范等)是编写规则的理想起点。
也可以通过/Generate Cursor Rules命令从现有对话生成规则。如果您进行了长时间的多轮对话并给出大量提示,其中可能包含值得复用的有用指令或通用规则。

MCP(模型上下文协议)
Model Context Protocol 是一个可扩展层,通过它您可以为Cursor赋予执行操作和获取外部上下文的能力。根据您的开发环境设置,可能需要利用不同类型的服务器,但我们发现以下两类特别实用:
- 内部文档:例如Notion、Confluence、Google Docs
- 项目管理:例如Linear、Jira
如果您已有通过API访问上下文和执行操作的现有工具,可以为其构建MCP服务器。以下是构建指南:https://modelcontextprotocol.io/tutorials/building-mcp-with-llms

自主收集上下文
许多用户正在采用一种强大模式:让智能体(Agent)编写短期工具,然后运行这些工具来收集更多上下文。这在需要人工审核代码的人机协作流程中特别有效。
例如,在代码中添加调试语句并运行后,让模型检查输出结果,就能使其获得静态分析无法推断的动态上下文。
在Python中,您可以通过以下方式指导智能体:
- 在代码关键位置添加 print("debugging: ...") 语句
- 使用终端运行代码或测试
智能体会读取终端输出并决定后续操作。核心思想是让智能体访问实际运行时行为,而不仅是静态代码。

关键要点
- 上下文是高效AI编程的基础,包含意图(您想要什么)和状态(现有内容)。同时提供两者有助于Cursor做出准确预测
- 使用精准的@符号上下文(@code、@file、@folder)精确引导Cursor,而非仅依赖自动上下文收集
- 将可复用的知识捕获为团队规则,并通过模型上下文协议扩展Cursor能力以连接外部系统
- 上下文不足会导致幻觉输出或低效,而过多的无关上下文会稀释有效信号。保持适当平衡才能获得最佳效果